So, just a few days ago I posted Learning Club 00: Set up your development environment (Getting started with R). There I made a mistake and decided to use R without thinking about the data set I would use. I am still happy I wrote the post because it can give all the R users in the learning club an introduction on how to setup their R environment and which resources to use. But still I have to update you about my environment 🙂
And since I don’t know what activities will come up in the learning club, at least now I have R and python available. So I am going to prep
Contents
NFL data
For the learning club, or at least the first tasks, I want to use NFL (National Football League) data. It is not so easy to get hold of sports data, since e.g. the TV channels charge lots of money for their APIs. So, after exploring programmableweb.com and mashape.com, I found that most APIs cost a lot of money. My boyfriend searched the web a little further and found the python library nfldb by BurntSushi which comes with a postgres DB that you need to install on your computer/server.
Database and server
The data is now stored in a postgres database on our debian server.
BurntSushi provides an ER diagram which can be useful for using the data.
Accessing the data
As already mentioned, the package nfldb provides several methods to access the data. The author also provides API documentation and a great wiki.
SQL
The data can be accessed via command line using psql:
psql -U nfldb
Then it will ask for your password:
Passwort für Benutzer nfldb:
Then you will get a command prompt:
nfldb=>
This is how you get help:
nfldb=>\?
This is how you get all tables:
nfldb=>\d
This is the output (sorry it’s in German):
Liste der Relationen
Schema | Name | Typ | Eigentümer
--------+-------------+---------+------------
public | agg_play | Tabelle | nfldb
public | drive | Tabelle | nfldb
public | game | Tabelle | nfldb
public | meta | Tabelle | nfldb
public | play | Tabelle | nfldb
public | play_player | Tabelle | nfldb
public | player | Tabelle | nfldb
public | team | Tabelle | nfldb
(8 Zeilen)
And this is how you get information about table “play”:
nfldb=>\d play
first_down | smallint | not null Vorgabewert 0
fourth_down_att | smallint | not null Vorgabewert 0
fourth_down_conv | smallint | not null Vorgabewert 0
fourth_down_failed | smallint | not null Vorgabewert 0
passing_first_down | smallint | not null Vorgabewert 0
penalty | smallint | not null Vorgabewert 0
penalty_first_down | smallint | not null Vorgabewert 0
penalty_yds | smallint | not null Vorgabewert 0
rushing_first_down | smallint | not null Vorgabewert 0
third_down_att | smallint | not null Vorgabewert 0
third_down_conv | smallint | not null Vorgabewert 0
third_down_failed | smallint | not null Vorgabewert 0
timeout | smallint | not null Vorgabewert 0
xp_aborted | smallint | not null Vorgabewert 0
Indexe:
"play_pkey" PRIMARY KEY, btree (gsis_id, drive_id, play_id)
"play_in_down" btree (down)
"play_in_first_down" btree (first_down)
"play_in_fourth_down_att" btree (fourth_down_att)
"play_in_fourth_down_conv" btree (fourth_down_conv)
"play_in_fourth_down_failed" btree (fourth_down_failed)
"play_in_gsis_drive_id" btree (gsis_id, drive_id)
"play_in_gsis_id" btree (gsis_id)
"play_in_passing_first_down" btree (passing_first_down)
"play_in_penalty" btree (penalty)
"play_in_penalty_first_down" btree (penalty_first_down)
"play_in_penalty_yds" btree (penalty_yds)
"play_in_pos_team" btree (pos_team)
"play_in_rushing_first_down" btree (rushing_first_down)
"play_in_third_down_att" btree (third_down_att)
"play_in_third_down_conv" btree (third_down_conv)
"play_in_third_down_failed" btree (third_down_failed)
"play_in_time" btree ((("time").phase), (("time").elapsed))
"play_in_timeout" btree (timeout)
"play_in_xp_aborted" btree (xp_aborted)
"play_in_yardline" btree (((yardline).pos))
"play_in_yards_to_go" btree (yards_to_go DESC)
Check-Constraints:
"play_down_check" CHECK (down >= 1 AND down <= 4)
"play_yards_to_go_check" CHECK (yards_to_go >= 0 AND yards_to_go <= 100)
Fremdschlüssel-Constraints:
"play_gsis_id_fkey" FOREIGN KEY (gsis_id, drive_id) REFERENCES drive(gsis_id, drive_id) ON DELETE CASCADE
"play_gsis_id_fkey1" FOREIGN KEY (gsis_id) REFERENCES game(gsis_id) ON DELETE CASCADE
"play_pos_team_fkey" FOREIGN KEY (pos_team) REFERENCES team(team_id) ON UPDATE CASCADE ON DELETE RESTRICT
Fremdschlüsselverweise von:
TABLE "agg_play" CONSTRAINT "agg_play_gsis_id_fkey" FOREIGN KEY (gsis_id, drive_id, play_id) REFERENCES play(gsis_id, drive_id, play_id) ON DELETE CASCADE
TABLE "play_player" CONSTRAINT "play_player_gsis_id_fkey" FOREIGN KEY (gsis_id, drive_id, play_id) REFERENCES play(gsis_id, drive_id, play_id) ON DELETE CASCADE
Trigger:
agg_play_sync_insert AFTER INSERT ON play FOR EACH ROW EXECUTE PROCEDURE agg_play_insert()
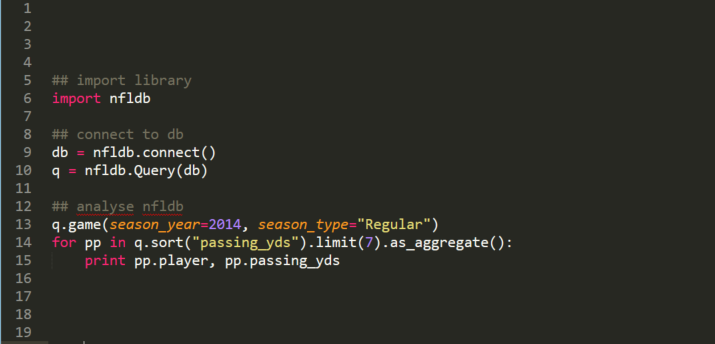
python
Of course, you can also access your database using the python package nfldb. To test if everything works, I copied one of the first examples on the github page and changed it a little.
## import library
import nfldb
## connect to db
db = nfldb.connect()
q = nfldb.Query(db)
## analyse nfldb
q.game(season_year=2014, season_type="Regular")
for pp in q.sort("passing_yds").limit(7).as_aggregate():
print pp.player, pp.passing_yds
I saved this file as 00data.py and called:
python 00data.py
The output was:
Drew Brees (NO, QB) 4952 Andrew Luck (IND, QB) 4761 Peyton Manning (DEN, QB) 4727 Matt Ryan (ATL, QB) 4694 Ben Roethlisberger (PIT, QB) 4659 Eli Manning (NYG, QB) 4410 Aaron Rodgers (GB, QB) 4381
Final words
I think the dataset is really cool because it has some relations and it is not just a data frame/matrix with samples and features like many training data sets. I think it will be interesting to analyze it, make visualizations and try to find some structure.
This was just a very introductory post because I just started using the db and the package myself. You will definitely get more insight when you follow my posts regarding the nfldb and the learning club.